SPSS回归分析(Regression Analysis)步骤
当我们需要通过可测的变量对未知的变量进行估计,以达到预测的目的,当一个变量依赖于另一个变量时,也就是一个变量如何随另一个(些)变量变化时,就用回归分析(regression analysis),那么回归分析(regression analysis)步骤是怎样的呢?下面用实例为大家分析。

在回归分析中,被估计或被预测的变量称为因变量(dependent variable)或反应变量(response variable)或结果变量,常用 y 表示。y 所依存的变量就是自变量(independent variable) 或解释变量(explanatory variable)或预测因子(predictor),用 x 表示。
在线性回归中,自变量可以有一个或多个,但是因变量只能有一个。
比如我们要研究如下问题:

操作步骤:
Analyze-Regression-Linear
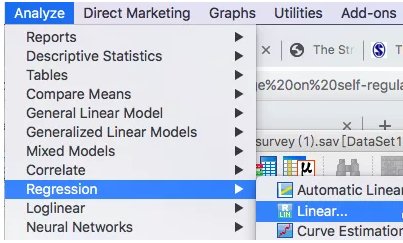
分别输入因变量和自变量,method部分默认选 Enter。它是指候选自变量全部纳入模型,不做任何筛选,Enter的结果是所有候选变量的P值都会显示出来。
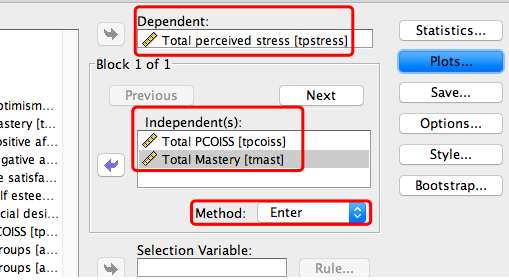
选择Statistics-勾选-Continue
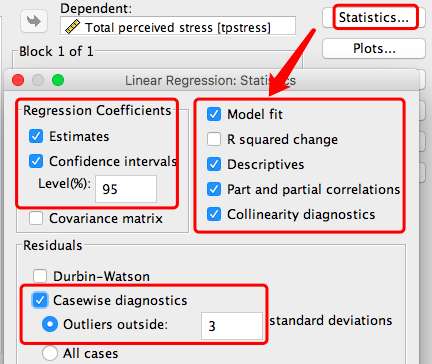
Options-选择Exclude cases pairwise-Continue
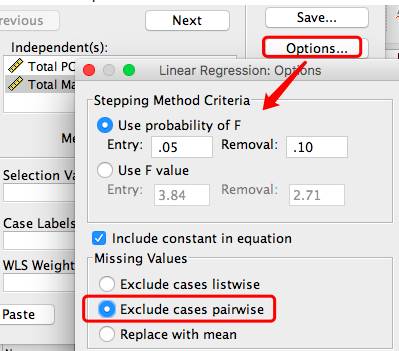
点击Plots选择Y, X轴和正态分布图。
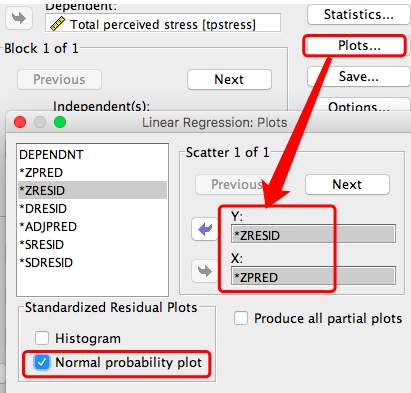
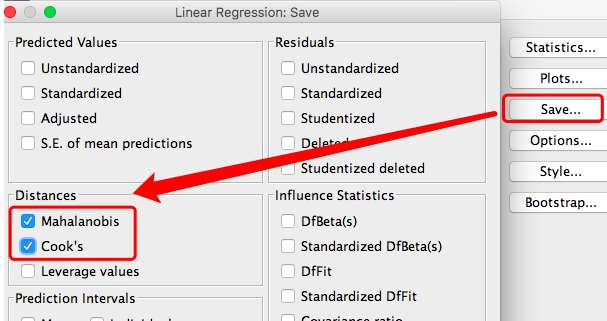
点击Save,选择Mahalanobis box 和 Cook’s,然后Continue-Ok
结果解释:
Step 1:检查假设Checking the assumptions
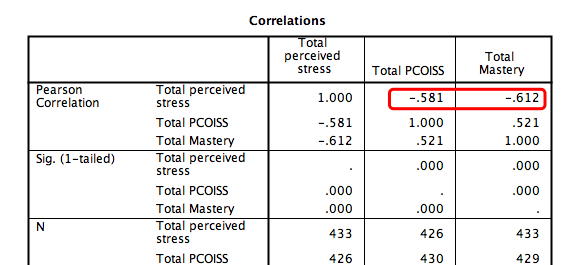
首先要检查两个自变量与因变量之间至少具有一定相关性。在下图中可以看出r都是大于3的,两个自变量与因变量之间都具有一定的相关性。
还要去看Tolerance 和 VIF的值,可以看出是否存在 multicollinearity 的问题。如果 Tolerance的值非常小,小于0.1,那么就可能有 multicollinearity 的问题;如果VIF大于10,则也会存在 multicollinearity 的问题。
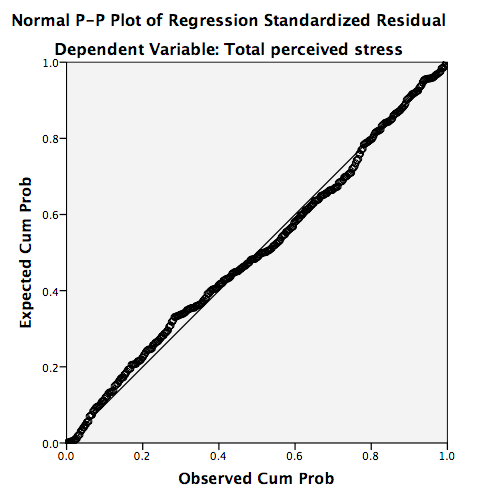
在Normal P-P Plot 图中,我们希望看到的是这些点位于从左下角到右上角的一条合理的直线上,这表明没有重大的偏离正常分布。在Scatterplot图中,希望残差(residuals)大致呈矩形分布,大部分分数集中在中心(沿0点)。在Scatterplot图上也能找到outliers。
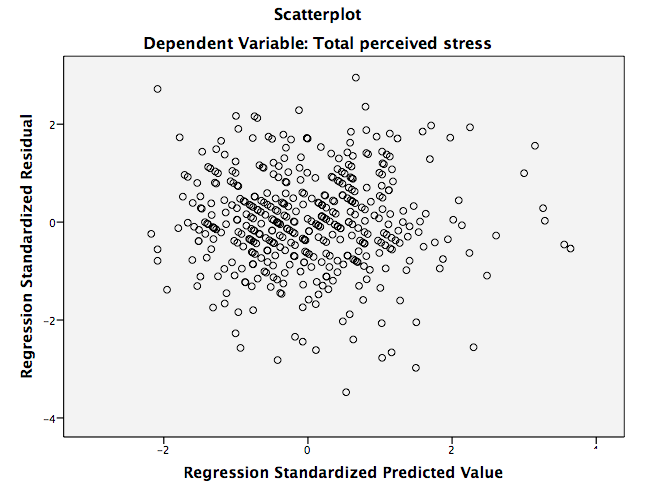
Step 2:评估模型 (Evaluating the model)
下图的模型汇总表中,最重要的指标是R方(R square),称为决定系数(coefficient determination),R square的取值在0-1之间,它反应了回归贡献的相对程度,即在因变量 y 的总变异中回归关系所能解释的比例。 本例中,R square=0.468, 说明自变量 Mastery and PCOISS可以解释因变量Perceived stress的46.8%,这个数据还是可以的。
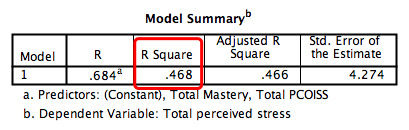
Step 3: 评估自变量 (Evaluating each of the independent variables)
模型中的哪些变量对因变量的预测有贡献呢?我们在 Coefficients 表中的 Standardised Coefficients的 Beta数值来看。Beta值越大,说明其预测能力越强,这里不用考虑数字前面的负号。本例中最大的beta coefficient等于 –.42,指的是Total Mastery,说明该变量对解释因变量的独特贡献最强。
我们还可以看下每个变量的 Sig.,如果变量的 Sig. 小于0.05,具有统计学意义,那么自变量对因变量的预测有重要的独特贡献。本例中 Total Mastery 和 Total PCOISS都有统计学意义。
以上就是关于SPSS回归分析(Regression Analysis)步骤内容,欢迎大家阅读,如果还有什么问题,欢迎大家给我们留言,如果需要各类SPSS作业代写服务,请联系网站客服。
